The AI Coding Subsidy Is Ending: What Usage-Based Billing Means for Your Team
59.4% of tokens go to agents re-reading their own work. Demand for AI compute is outpacing supply, and prices are already climbing. The AI coding subsidy is ending. Here's what comes next.
In this article
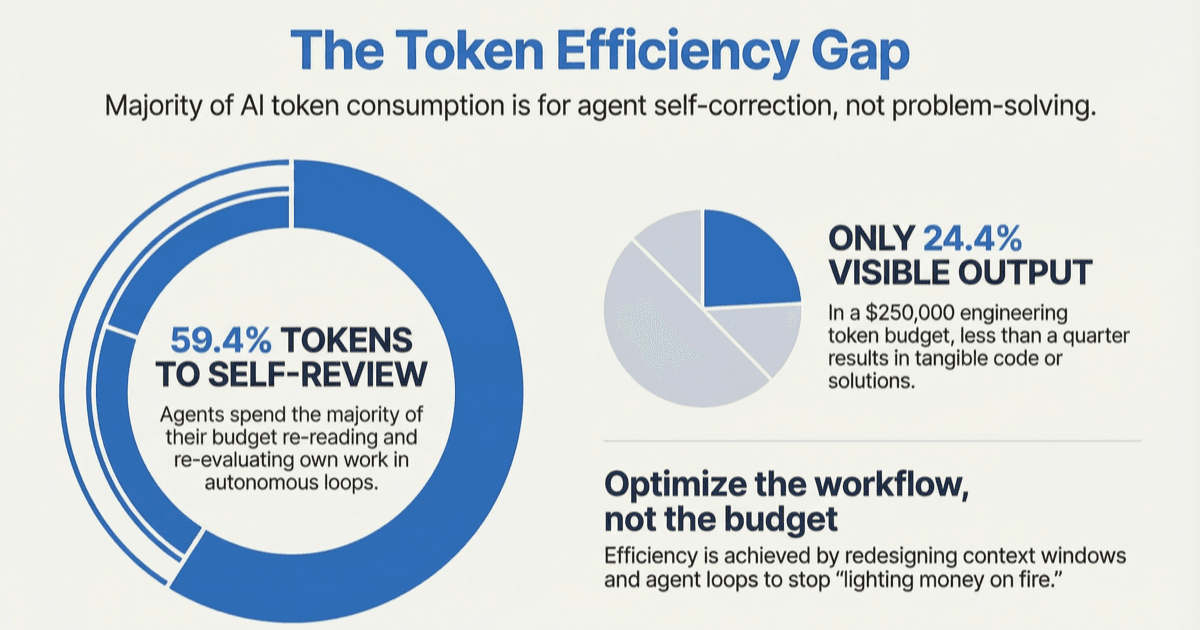
59.4% of your tokens go to agents re-reading and re-evaluating their own work
An Arxiv paper from January 2026 analyzed token consumption patterns in software development cycle with LLMs and mapped where tokens actually go in agentic software engineering: 59.4% of token consumption went to the agent re-reading and re-evaluating its own work. Not writing code or solving problems. Just reviewing and re-evaluating its own output.
That's where most of the money goes, and it's also why flat-rate subscriptions don't make financial sense. A $200/month plan was built for humans typing at human speed with human work logic. Agentic AI doesn't work that way. Tools like Claude Code, Cursor's agent mode, and plugins like Ralph Wiggum (which runs an AI agent in an autonomous loop until the task is done) can solve genuinely difficult problems. A $50,000 project completed for $297 in API costs. An entire React v16-to-v19 migration done in a 14-hour overnight session without human input.
But those same techniques can also run for days, burning through thousands of dollars while the agent loops on problems it can't solve. Without a human who understands how to scope the work, set boundaries, and refine the output, these tools don't just light money on fire. They produce confident, broken code that creates more work than it saves.
To be clear: the "subsidy" isn't across all of AI. Per-token API pricing has always been a straightforward market transaction. Providers charge a markup, enterprises pay it, and the math works. What's subsidized is the flat-rate subscription: $20/month Pro plans, $200/month Max plans, unlimited-use promises. Those were priced for adoption, not sustainability. You can already see it playing out. In recent weeks, Anthropic has been quietly scaling down session limits for Max subscribers and the community backlash has been significant. The response? An extra $100 of usage on top of the reduced limits. It reads less like a reversal and more like an attempt to soften the squeeze while it continues.
It's a part of the reason Anthropic deployed server-side blocks and started banning Max subscribers who were multiplying access. Boris Cherny, the creator of Claude Code, addressed this directly:
"One of the things we do to serve a lot of customers is to optimize the way subscriptions work to serve as many people as possible with the best model. Third-party services are not optimized in this way so it's really hard to do sustainably."
Third-party harnesses bypass prompt caching and other internal optimizations that make flat-rate serving viable at all. Anthropic can only make subscriptions work when they control the full stack. The direction for serious agentic work is APIs. And APIs have a very different price tag.
It's Happening: The June 2026 Turn
When we first wrote this, the shift was a forecast. By June 2026 it was a schedule. GitHub moved every Copilot plan to usage-based billing on June 1, swapping its old request units for metered “AI Credits” that draw down as you spend input, output, and cached tokens. Code completions stay free, but agent work now runs against a credit balance.
Google followed the same month. On June 18, Gemini Code Assist retired its free individual tier and moved to a seat price with token usage billed on top. The pattern is consistent across vendors: a flat seat fee is becoming a floor, and the heavy agentic work rides on metered tokens above it. OpenAI made the same move on Codex in the spring, shifting from per-message pricing to token-aligned credits.
Anthropic now charges its Enterprise customers a seat price plus usage at standard API rates, so the teams running agents hardest feel it most. Reporting through the spring put heavy users' bills at two to three times what they were under the old flat pricing.
It isn't a clean one-way march. Anthropic announced in May that programmatic Claude Code usage, the headless runs, the Agent SDK, and GitHub Actions, would move off subscription limits onto a separate metered credit, then cancelled the change on June 15, the day it was set to take effect, saying it would rework the approach. Read that as a sign of how much pressure is on pricing right now, not that the direction reversed. The fight to keep subscription users is real, and so is the cost underneath it.
The cost shock is already showing up at scale. Uber's CTO said the company's full-year 2026 AI budget was gone about four months in, after rolling Claude Code out to roughly 5,000 engineers, and Uber capped individual AI spend at $1,500 a month per engineer. Microsoft is moving its Experiences and Devices group off Claude Code onto GitHub's Copilot CLI by the end of June. These aren't small shops. They're the companies with the most leverage, and they're already re-planning around the bill.
Tokens Are the New Headcount
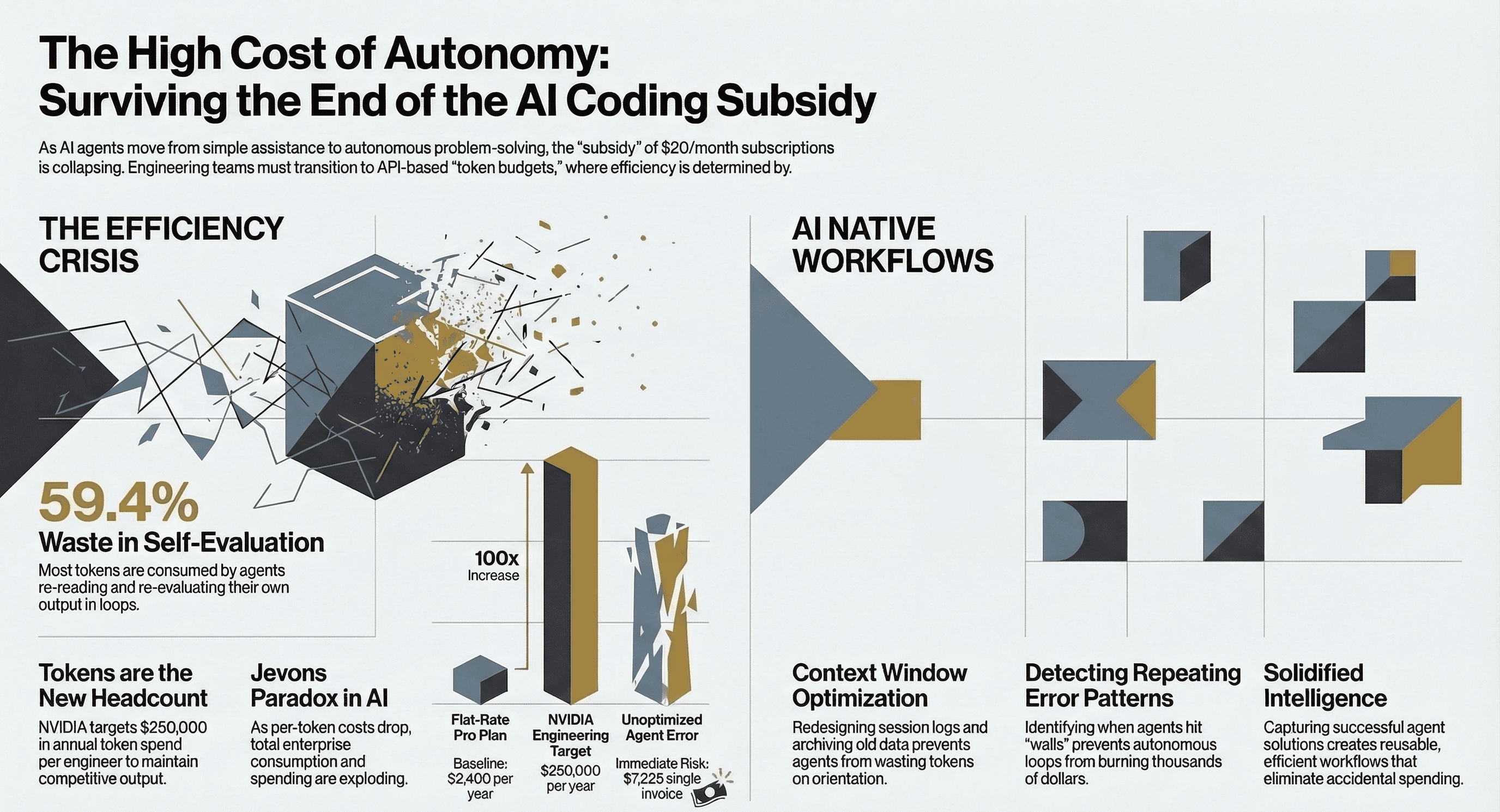
Jensen Huang made this concrete at GTC 2026. Every NVIDIA engineer who makes $500,000 a year should consume $250,000 in AI tokens on top of their salary. If they don't, Huang says he'd be "deeply alarmed." A $200/month subscription is $2,400 a year. Jensen's number is 50x that. NVIDIA is trying to spend $2 billion annually on tokens for their engineering team alone. Token budgets are already "one of the recruiting tools in Silicon Valley." My first reaction was not of surprise but more of a feeling that no one is ready to accept this reality yet.
Meanwhile, teams are shrinking and the work isn't. As headcount gets cut (outsourcing first, then hiring freezes, then layoffs) the gap gets filled by AI agents running on API tokens. That budget isn't optional. It's the replacement cost for the people who left.
And you can't always see what you're paying for or predict how much you would pay. Cursor built Composer 2 on Kimi K2.5, a model costing 10x less than Claude, and didn't disclose it until Kimi's own engineers reverse-engineered it. Users report Cursor silently switching their model selection to "Auto", routing to cheaper models, allegedly without consent. If your tools aren't transparent about what's running under the hood, you will have a very hard time managing the spend.
Token consumption is quickly becoming the measurement of how effective engineers are being with their output. And while all of us know that working with AI coding tools, quantity is no assurance for quality, there is a growing expectation to do more with less which often can be superficially translated to token quantity. It is clear that a company like NVIDIA would have an incentive to motivate that type of thinking.
Per-token costs dropped 92% in two years. Yet AI spending for enterprise is growing dramatically year over year. Both in infrastructure and direct AI spend for tokens. Anthropic has over 1,000 companies spending $1,000,000 or more on API tokens this year alone. But here's what most people miss: API and enterprise contracts make up 70-75% of Anthropic's revenue. Subscriptions, the Pro and Max plans everyone argues about, account for just 10-15%. The enterprise API business is where the money is. The subscriptions were never the business model. They were the acquisition channel.
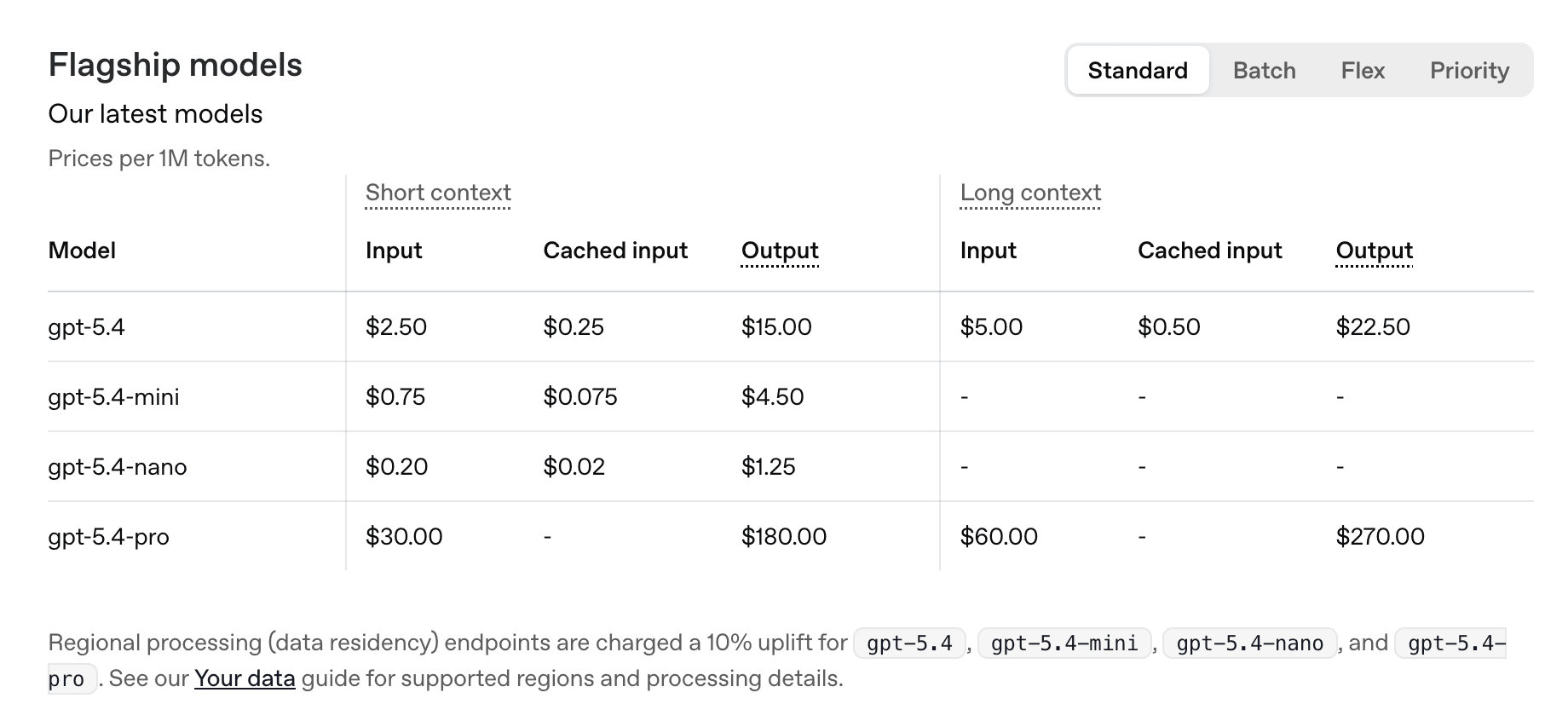
When GPT-4 launched in March 2023 it launched at $30 per million input tokens. Today, GPT-5.4 costs $2.50 per million. But at a closer look, GPT-5.4 is actually more expensive than GPT-5.2 was. And the Pro tier sits at $30 per million input, right back where GPT-4 started and can go as high as $270 gpt-5.4-pro Long context output tokens! The race to the bottom may already be over.

Worldwide AI spending is projected to hit $2.5 trillion in 2026 including vast infrastructure spend. Enterprise AI spending alone tripled last year.
When DeepSeek launched in January 2025, Satya Nadella recognized this pattern immediately: "Jevons paradox strikes again." Make tokens cheaper per unit and total consumption explodes.
That's what every AI company is banking on but that has its limits as the race to the bottom must end at some point. OpenAI projects revenue will hit $280 billion by 2030. Anthropic's Claude Code alone accounts for $2.5 billion ARR, doubling since January. These companies aren't expecting you to spend less.
And right now, many of the plans individual people and small organizations use are priced below cost. Sam Altman admitted OpenAI loses money on the $200/month Pro plan while Anthropic's CEO put it bluntly: "If I'm just off by a year in that rate of growth, or if the growth rate is 5x a year instead of 10x a year, then you go bankrupt." The margins on timing are that thin. One Cursor user received a $7,225 API invoice from legitimate usage.
When Demand Outpaces Compute
There's a structural force behind those rising prices that goes beyond business decisions. Demand for AI compute is growing faster than anyone can build the infrastructure to serve it.
Anthropic's run-rate revenue went from $1 billion in December 2024 to $30 billion by April 2026. That's $21 billion added in a single quarter. The company had 500 enterprise customers spending over $1 million each in February. Two months later, that number doubled to over 1,000.
That kind of demand creates a physical problem. Anthropic just signed a deal with Google and Broadcom for multiple gigawatts of next-generation TPU capacity. It's their largest compute commitment ever. It won't come online until 2027. In the meantime, capacity can't keep up: subscribers see reduced session limits, response quality degrades during peak hours, and enterprise waitlists grow.
The AI industry is projected to spend $690 billion in capital expenditure in 2026 alone. That infrastructure cost gets passed through to token pricing. When chips, power, and data center capacity are the bottleneck, the cost floor rises for everyone.
The subsidy isn't ending because companies chose to stop being generous. It's ending because the physics of supply and demand caught up, despite the great competition for market share. API pricing has roughly 10x markup over actual compute cost. That math works. What doesn't work is flat-rate subscriptions where a heavy user on a $200/month plan burns through $500 or more in compute, while the infrastructure to serve those tokens costs more every quarter. We were the marketing campaign, not the customers. For serious agentic work, the direction is usage-based, per-token, and transparent. It's also expensive.
The Road to AI Native
Everybody's talking about using AI. Almost nobody is talking about educating their team on how to use it well.
As Jensen Huang said, there is already a calculation in place for the type of budgets engineers will get to properly do their jobs. But handing your team a $250,000 token budget without teaching them how agents actually work is like giving every employee a company credit card with no expense policy.
Our founder spends $15k a month on tokens and says he feels like he's in the B group. He's not being modest. Some teams are burning hundreds of thousands. But his insight, from living this daily, is that 95% of those tokens probably aren't worth the money. Some actively cause damage and rework. An agent that confidently writes broken code costs you twice: once for the tokens, again for the debugging.
The difference between a team that burns through its entire budget and a team that gets the same output for a fraction isn't the model they're using. It's whether anyone taught them how the tool works and how to make the best of this new superpower.
I learned this the hard way. I built session logs, structured context files that Claude Code loads at the start of every conversation so it picks up where the last session left off. Worked great. Then we sat with the team and realized the session log itself was eating a massive chunk of the context window just to load. The agent was spending tens of thousands of tokens on orientation before doing any actual work.
The fix wasn't a bigger plan or a better model. It was understanding how context windows work and redesigning the process: restructuring the log, archiving older sections, keeping the active window lean. Breaking down one agent into multiple specialized agents, more similar to a relay race. A workflow decision, not a spending decision.
That's what being AI Native looks like. Not spending more. Not chasing the latest model. Understanding the mechanics well enough to design workflows where the agent and engineers operating it spends tokens on work, not running circles trying to get something done. In large organizations this understanding will require coordinated effort, not individual solo exploring. This type of coordination, or lack thereof, could lead to great saving or great waste.
How Flowpad Fits the Picture
Flowpad detects and debugs repeating error patterns (agents hitting the same wall, trying the same fix, failing, looping) and stops them from happening. It captures solutions that work and turns them into reusable workflows your team can share with each other. It lets engineering leads configure agent workflows top-down, so the team operates from a shared playbook instead of every developer figuring it out on their own. Over time, your organization's AI workflows become solidified: repeatable, reliable, and efficient by default instead of by accident.

It gives you and your team visibility into what your agents are actually doing: tool handoffs, context management, tracing and debugging in real time. Every step, every file read, every decision, every loop. Not how much was spent, but what exactly happened. When an agent burns 50,000 tokens on a task that should have taken 5,000, you can see exactly where it went wrong and optimize for the next run. This compounds in agent output quality over time. That is the whole point: you can see what your team's AI agents actually spend their tokens on, then fix the workflow instead of guessing.
The session log optimization I described earlier took months of personal experience to figure out. Flowpad makes that kind of learning automatic and team-wide. One engineer's hard-won insight becomes everyone's default workflow.
Most tokens are wasted not because the AI is bad, but because nobody designed the workflow around how it should actually work for your product or team. If you're building skills for your agents, you already know that getting them to run reliably is not easy. Without that coordination, every developer builds their own approach, produces inconsistent output, and the PR review becomes the only place anyone catches the problems. There are good tools for reviewing PRs. But by the time code gets there, the time is already wasted and the rework cycle is baked in. Fix the workflow upstream and the same team, with the same tools, gets dramatically more output for dramatically less spend.
We are before a test that will change the way we work in high-tech. The era of cheap tokens is ending, and within a few months every engineering team will face a choice: budget for another engineer, or budget for more tokens.
An inefficient engineer with AI tools doesn't just waste money. They cost the organization three times. The tokens they burn on loops, rework, and agents running in circles. The product delays that come from AI-generated output that wasn't scoped or reviewed properly. And the salary, benefits, and overhead that were always there and aren't going away.
For enterprises on usage-based API pricing, this isn't theoretical. It's on this month's invoice. Without visibility into what your agents are actually doing, how your engineers are working with tokens, and where your agentic workflows are breaking down, optimizing spend is guesswork. Observability becomes key. Not token dashboards. Understanding how your team actually operates.
We're running early pilots. If you want to see what this looks like on your team, book a demo today.
Written by The Builder
Ami Levy
Product marketer. Building Flowpad with Claude Code.
How We Built a Production Website with Claude Code: No Agency, No Dev Team
A GTM lead, a senior dev reviewer, and Claude Code replaced a web agency. Here's the architecture behind Flowpad's website — and why the stack matters more than the tool.
Claude Code Source Code Leak: What 512,000 Leaked Lines Reveal (2026 Analysis)
512,000 lines of Claude Code accidentally went public. We checked every viral claim against the actual code - here's what was real, overstated, or invented.
5 first things we did with Fable 5 and why you should too
Five real tests of Fable 5 on our own codebase: security, performance, QA, refactoring and async. The numbers, the wins, and the open problems.