Deleting 40K lines of code failed on Opus 4.7, how did it do on 4.8?
In this article
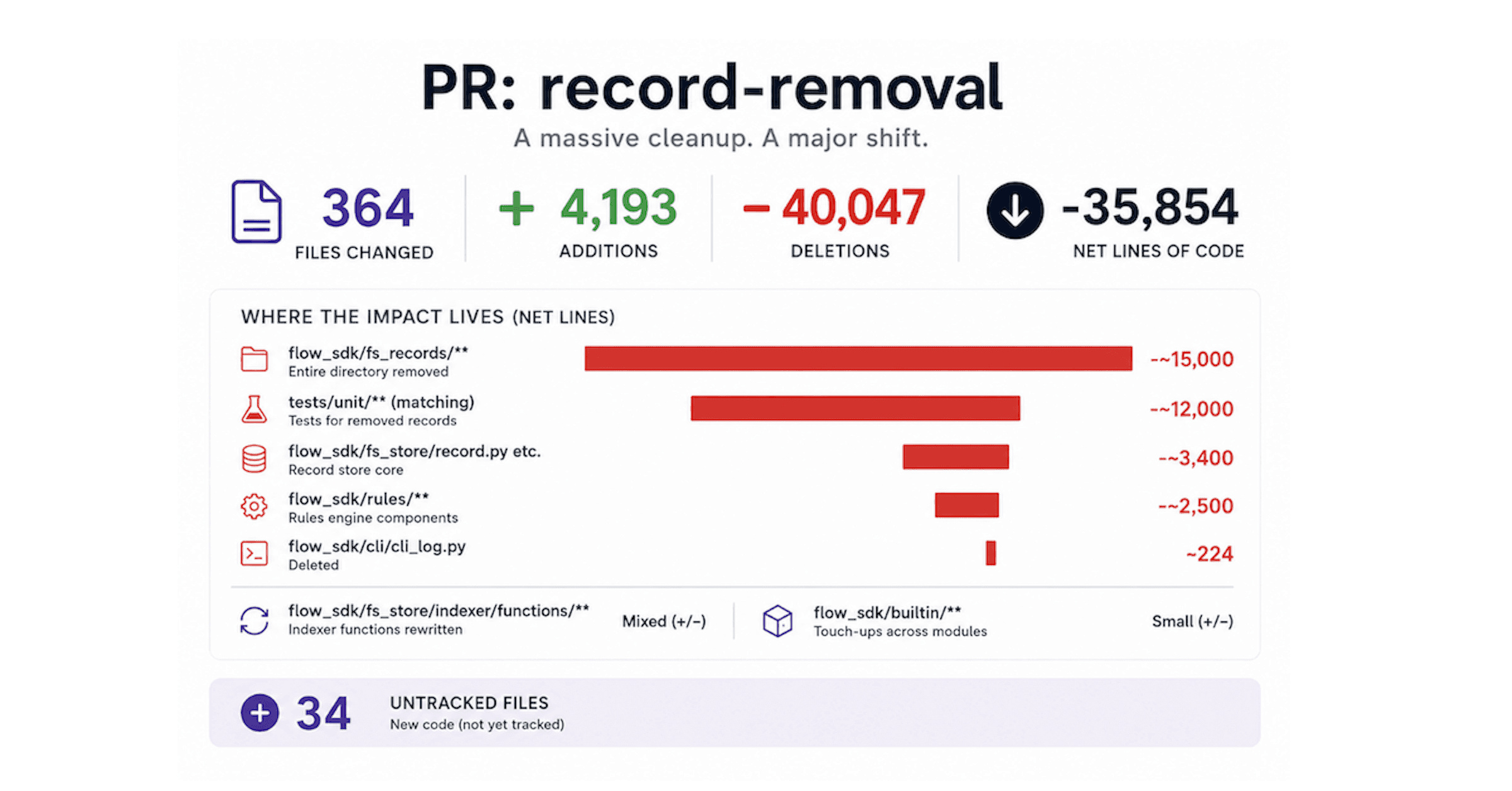
Opus 4.7 first attempt - Bulk migration failed
Since a lot of the refactor is repetitive in nature, letting Claude Code write scripts, show success in one and then apply it to the others looked promising, but it only looked promising from the outside, internally, with time, each record has started to develop its own "world", therefore the method of "bulk migration" failed and some re-architecture was needed, one that is not possible through scripting and requires long, heavy LLM running for days. Running LLM for days is a new territory for us.
Opus 4.7 second attempt - Teams and subagents failed
The next attempt was launching a bunch of subagents, each responsible for migrating specific records. This approach solved the issue per entity, yet overall it failed to generalize the proper architecture, leading to a different kind of bloat, smaller but not remotely what's needed. Moreover, once I went into the details of each entity type story, it was clear the actual solution is removing all of them. Opus 4.7 struggled, failing to complete the plan over and over, constantly drifting from the main path into issues it encountered along the way, real issues. Tests were not passing.
The problem
We are developing a knowledge collaboration platform that is native to both agents and humans and where do agents and humans hang out together these days? Git, CLI and Markdown with the file system being a fundamental communication system.
We have chosen to manage the record of our system as file system first, mostly since agents are already working like that on your system, whether it's a Claude Code session, skill or agent definition, they are all entities on the file system (front-mattered markdown) and the code itself, that is everywhere, is also files and folders in its core.
But working with files is not convenient, you can not create relationships between entities, maintaining shared state between multiple machines is challenging and management is not trivial (search and query of that Claude session from last week).
The file system is ground truth and we required the index (local SQLite db) to be recoverable, it's hard to control agents' behavior and files over git are more resilient to YOLO mode fatal mistake. Reindex and continue where you left off if Claude Code suddenly decides "No more db for you".
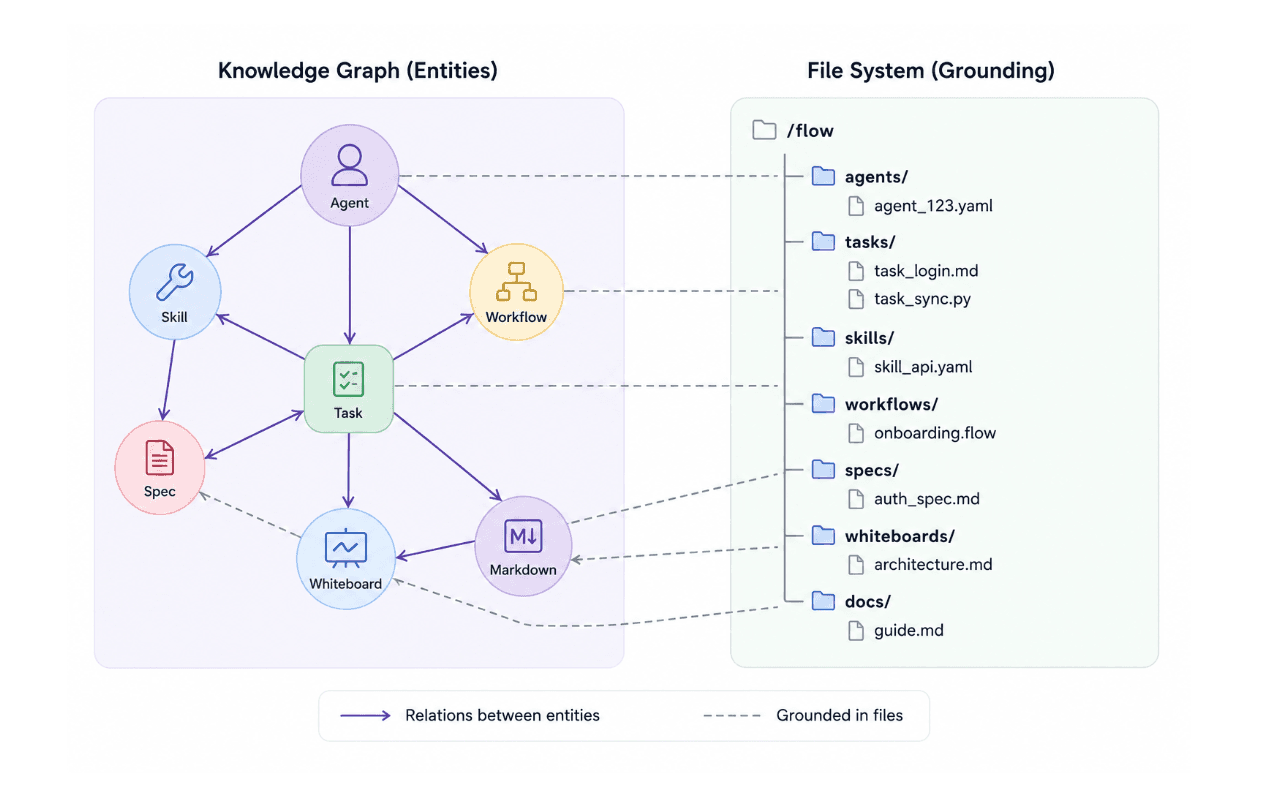
The initial connection was a simple record base class that manages the files of the record, and some simple inheritance, more for typing and order rather than meaningful functionality; however, prompt by prompt, the file system management has started to grow and the coding agent, as a coding agent, is not efficient in compressing code, yet the replications over different entities were not horrible… until it was. These machines are very good in generating code and very bad in generating good code. The main reason is that by their nature they are decompressing information and at the end of the day, AI and coding is all about compressing concepts, requirements and logic into code. Now we are in the good old place of having a major refactor waiting and timing is never good for major refactoring.
Opus 4.8 - Success?
When Opus 4.8 came out, I immediately reignited this effort with it. A few hours later, while I was away, I got my first pass, with only a few tests failing. I then reviewed the code and it looked as I expected, which felt like quite a surprise.
Another 30 min and 100% pass rate on all tests. It was time to move to the real test: manual regression.
Testing
How do you know it's ok? 40K lines of code is not something you review manually and just the tests are not enough.
The manual regression, worth posting by itself, is a long list of scenarios testing the app. These are different kinds of tests. They are markdown workflows. They can contain very complex steps (like setting up 2 instances of the app + server to test communication). The manual regression is not reliable and you actually have to dig into the results to validate the reported success is actually real (Claude Code always reports success, never really making it 100%). Manual regression passed. Reviewing the results, it is on par with the previous run.
Final validation and merge candidate
The next phase was running the old system indexing and scanning against the new one, expecting byte level match. 2 hours and it was done.
Then deeper manual code review. Looks fine.
Finally, go for heavy manual QA. It is working, yet there are still bugs here and there. It looks like we will merge this PR.
If you want to see what we are building on the other side of this refactor, book a demo.
Written by The Architect
Eran Shlomo
Cofounder & CEO of Langware Labs. Writes about AI strategy, enterprise technology, and the technical architecture behind AI coding tools.
5 first things we did with Fable 5 and why you should too
Five real tests of Fable 5 on our own codebase: security, performance, QA, refactoring and async. The numbers, the wins, and the open problems.
Machine Learning 2.0
30 minutes to demo, 3 years to production. Why prompt tweaking won't survive. How ML 2.0 reframes AI workflow development.
From Neurons to Networks
AI agents aren't a factory assembly line. Complexity theory explains why they keep breaking, and why observability beats control.